
Scoring Midterm Election Forecasts
Scoring Midterm Election Forecasts
Performance metrics for PredictIt, FiveThirtyEight, and Manifold Markets

[Posting on November 11, 2022 – at this point several elections are still unresolved (NV and AZ Senate and Governor races, AK Senate, GA Senate, control of Senate, and control of House). I’m doing the analysis with an incomplete dataset for now, since I don’t know how long it’ll take for these races to be called – and Georgia is having a runoff so that one won’t be decided until December. Once these races are resolved, I’ll re-do the analysis and update this post. But for now here are some preliminary results. Probably the accuracy scores will get slightly worse when these final races are included, since they were more difficult to predict.]
[UPDATE November 20, 2022 - the results now include all forecasts except for the GA senate (which is going to a runoff and won’t be resolved until December). After this update, accuracy scores are slightly worse, since the races that took the longest to call were also the hardest to predict. But general trends are mostly the same.]
[FINAL UPDATE January 2, 2023 - just re-did the analysis including the results of the Georgia runoff. Sorry about the delay! General trends are mostly the same after this update.]
Introduction
The goal of this post is to report evaluation metrics for some forecasts of the November 2022 midterm elections in the US. Specifically, I’ll focus on three sites: PredictIt, FiveThirtyEight, and Manifold Markets. In addition to being three of the most popular forecasting sites, I think these three are an interesting combination because they each take a different approach. PredictIt is a real-money prediction market, FiveThirtyEight is the personal forecasting project of expert data scientist Nate Silver, and Manifold Markets is a prediction market site that uses play-money instead of real money.
I collected the data the old-fashioned way – by actually checking these sites two weeks, one week, and one day before election day, typing the prices into an Excel spreadsheet, and then doing the same for the outcomes after the elections were called. This dataset and the Python code I used for the analysis are all available on my Github in case anyone wants to do their own analysis. I also documented my data collection with screen-capture videos on the days that I checked these sites, in case anyone wants to check and make sure I’m not making these numbers up. This video documentation is available on my Youtube channel.
I also collected the data for another site, Election Betting Odds, but decided not to include it in this report because their forecast for the state-level senate and governor races was taken directly from PredictIt, just with an additional bit of processing. But data for Election Betting Odds is included in the dataset on my Github page if anyone is interested.
The first analysis I’m going to report is a comparison between PredictIt and FiveThirtyEight, looking only at midterm questions for which both sites gave a forecast (so that it’s a fair comparison). I’ll compare the sites to each other, and to two controls: a no-skill control, and a semi-skilled guess-the-incumbent-every-time control. The reason Manifold Markets is left out here is because there are many questions for which PredictIt and FiveThirtyEight both gave a forecast and Manifold Markets did not.
The second analysis is a comparison between PredictIt and Manifold Markets, using the subset of questions for which both gave a forecast (a smaller set of questions than in the first analysis). Again, this is a fair comparison, looking at forecasts on the same questions, recorded at the same time points. This comparison is especially interesting because PredictIt is a real-money market and Manifold Markets is a play-money market, so it may give us a hint about how the role of financial incentives for accuracy compared to reputation-based incentives for accuracy – although I think there is too little data here and too many other variables (trading volume, etc) to draw any strong conclusions based on this report alone.
Anyway, I’m going to start off with the results (since that’s probably the only thing a lot of people want to see), and then discuss the methodology afterwards for those who are interested. So if you’re confused by terms like “calibration plot” and “Brier Score” just hang on and I’ll explain those in the Methodology section.
I’m going to be reporting the results here mostly without commentary. I think my contribution with this post is the data collection (which was pretty tedious) and number crunching, and I don’t have much to say in terms of why the forecasts performed the way they did.
Also, I would be super cautious here about extrapolating from these results. The dataset is just too small to draw any strong, general conclusions about the relative performance of PredictIt, FiveThirtyEight, and Manifold Markets. However, if people are interested in this type of analysis, I’ll keep doing it during future election cycles, and maybe some consistent patterns will emerge.
Results 1: PredictIt and FiveThirtyEight
This section will compare the performance of PredictIt and FiveThirtyEight. Importantly, this is a fair, apples-to-apples comparison, looking only at questions for which both sides gave a forecast, and comparing forecast probabilities recorded at the same time points: two weeks out, one week out, and the day before the election.
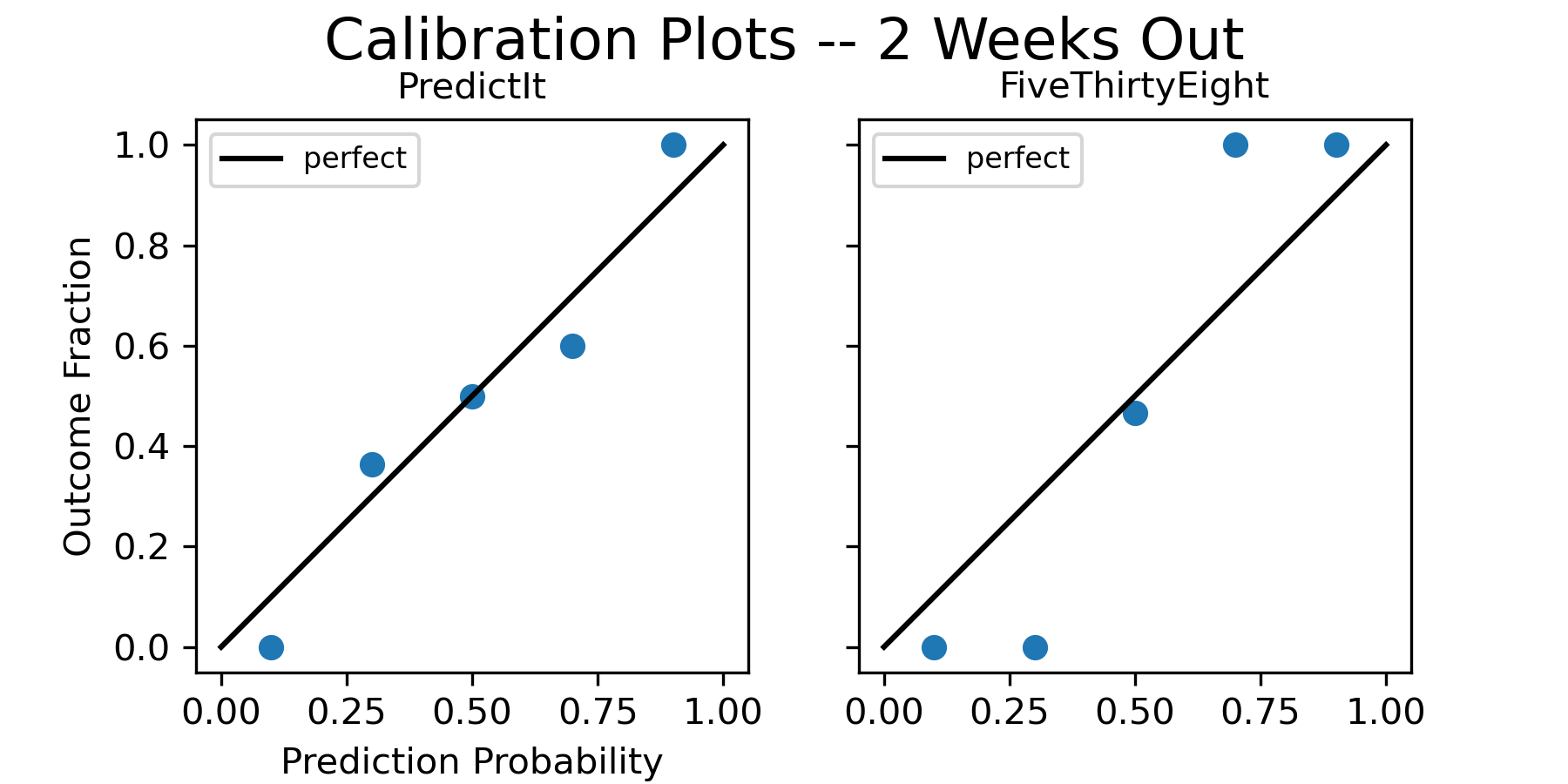
Let’s start off with some basic calibration plots. Again, if you don’t recognize this type of plot, please see the Methodology section at the end! Below are the calibration plots at 2 weeks out for both forecasts.
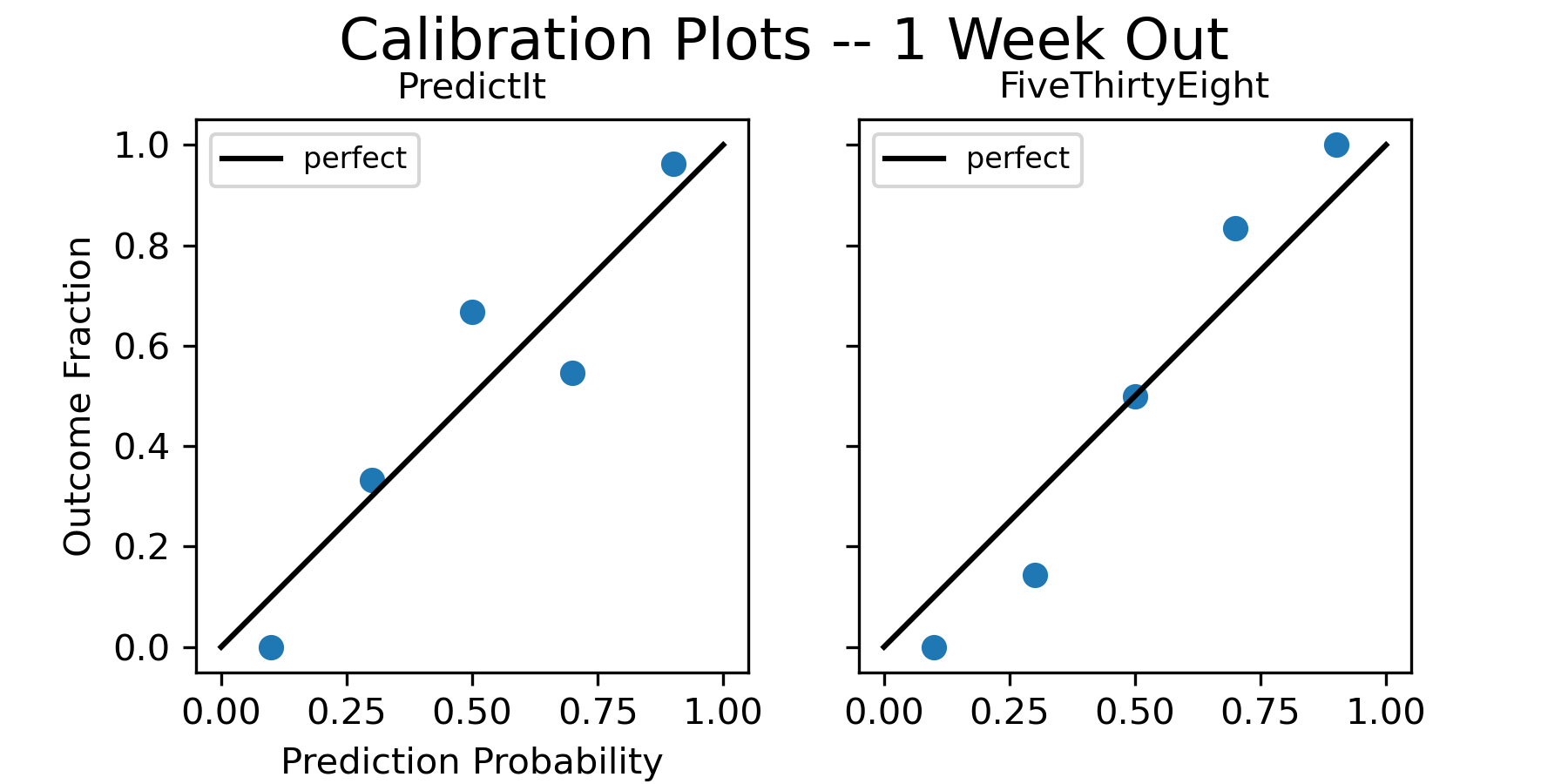
Here are the calibration plots at 1 week out:
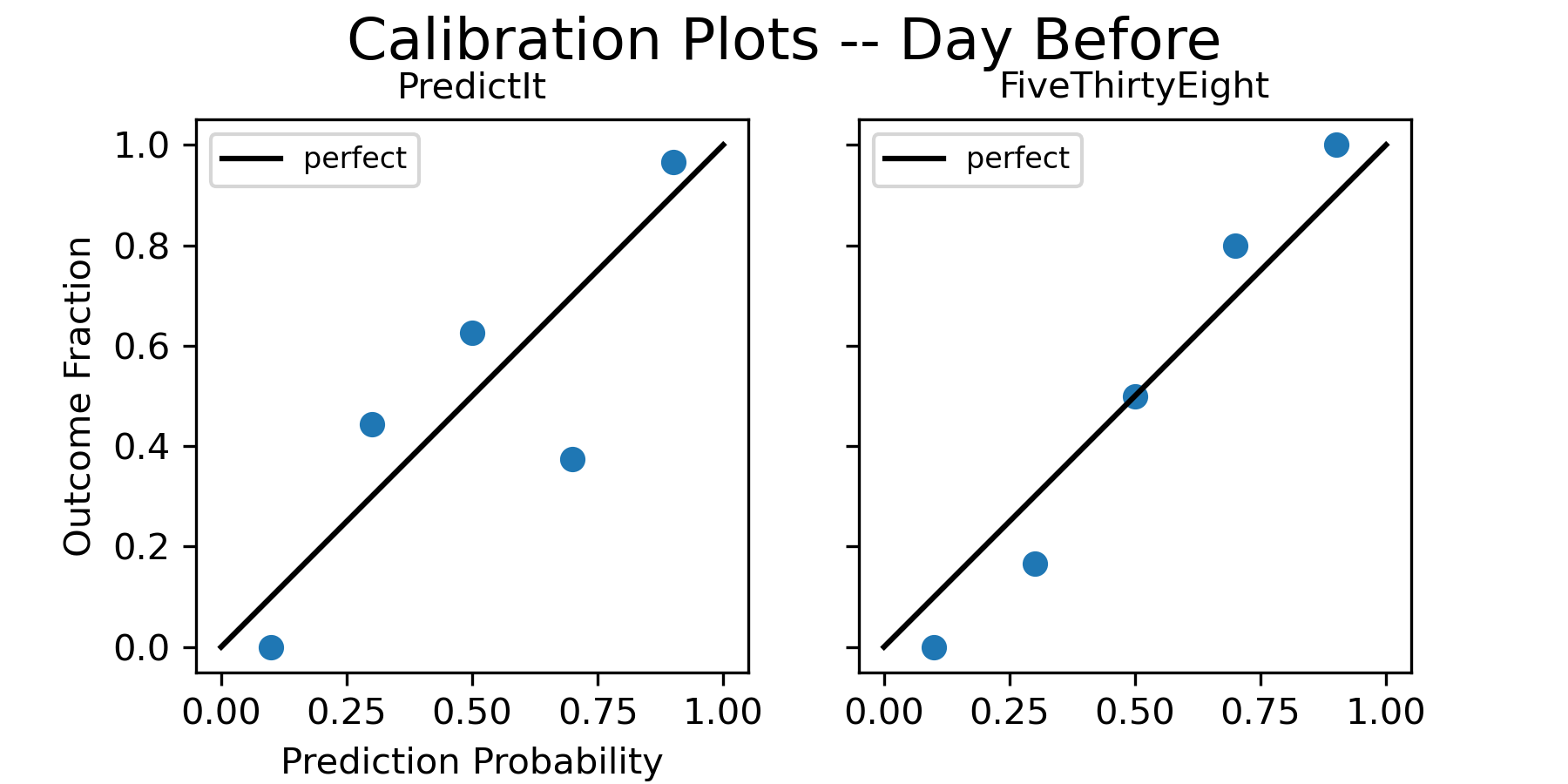
And here are the calibration plots the day before the election:
In addition to visualizing forecast performance with these calibration plots, we can also score the performance numerically with Brier scores. If you don’t know what a Brier score is, we’ll discuss this further in the Methodology section. For now, just think of it as a measurement of a forecast’s error – the lower the Brier score is, the better. Below is a table of Brier scores for both of the forecasts and both controls, at each time point:
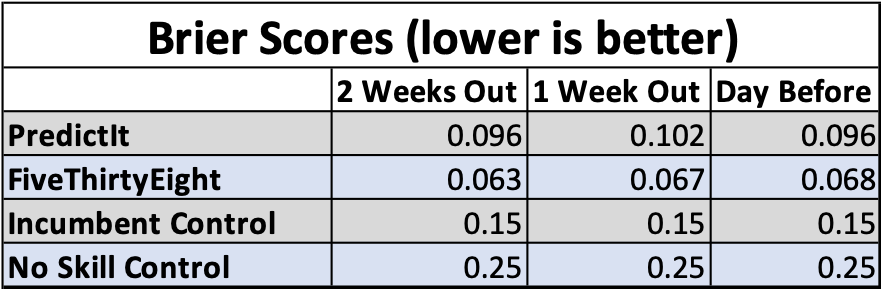
But wait a minute – is something wrong here? In the calibration plots, it looks like PredictIt is better calibrated than FiveThirtyEight, but we can see in the table that FiveThirtyEight actually had the better Brier scores. At first I was confused by this and thought I had a mistake in my code somewhere, but after looking into it I realized what’s going on. You can’t tell in the calibration plots, but looking at the data spreadsheet reveals that FiveThirtyEight had more forecast probabilities in the 0.1 and 0.9 bins compared to PredictIt, which all turned out to be correct. This detail is lost in the visualization, but it’s why the calibration plots look better for PredictIt even though the FiveThirtyEight forecast was actually more accurate.
[UPDATE November 20, 2022 - after including later results for the races that took a long time to call, FiveThirtyEight’s calibration plots look better than PredictIt at 1 week and 1 day before the election. However the point on methodology still stands, and the plots at 2 weeks out are still an example of the forecast with the seemingly worse calibration plot actually being more accurate.]
So an important takeaway from these results is that we need to be careful comparing forecasts with calibration plots — going by the visualization alone can be misleading if they have different binned forecast distributions. If the calibration plots seem to contradict the Brier scores, we should trust the Brier scores since they’re a straightforward calculation of error that don’t rely on an arbitrary binning strategy.
On another note, when I first looked at the forecast probability and outcome data, it looked to me like a binary classification machine learning problem (classifying whether an event is going to happen or not), so I wanted to also include ROC curves and AUROC scores in this analysis. However, when I actually plotted the ROC curves on this dataset, I realized they’re actually not an appropriate metric for scoring probabilistic forecasts, so I ended up not including them. Is anyone interested in hearing more about this? If at least one person is interested, I’ll make another post with the ROC curve results for this dataset and explain why this evaluation metric is inappropriate.
Anyway, I’m not including ROC curves here, but the code for plotting them is on my Github if you want to try it yourself.
Results 2: PredictIt Subset and Manifold Markets
This section will include performance metrics for PredictIt and Manifold Markets. The reason I didn’t just do a three-way comparison between PredictIt, FiveThirtyEight, and Manifold Markets is that the Manifold Markets forecasts included fewer questions than the PredictIt and FiveThirtyEight forecasts. So in order to do a fair comparison here, I’ll be comparing the smaller subset of questions for which PredictIt and Manifold Markets both gave a forecast.
Again, let’s start off with some basic calibration plots. Here are the calibration plot two weeks out from the election:
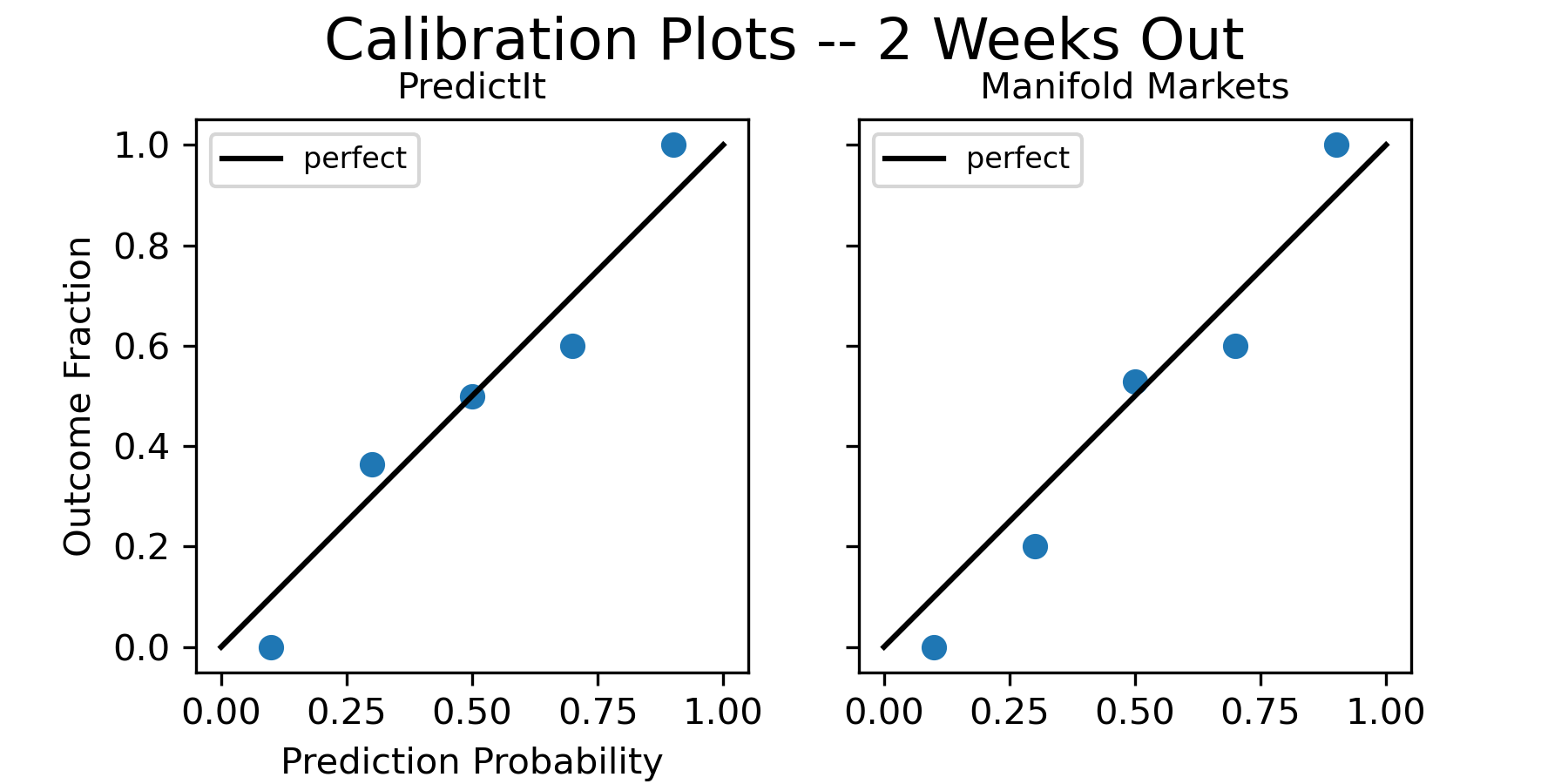
Here are the calibration plots one week out from the election:
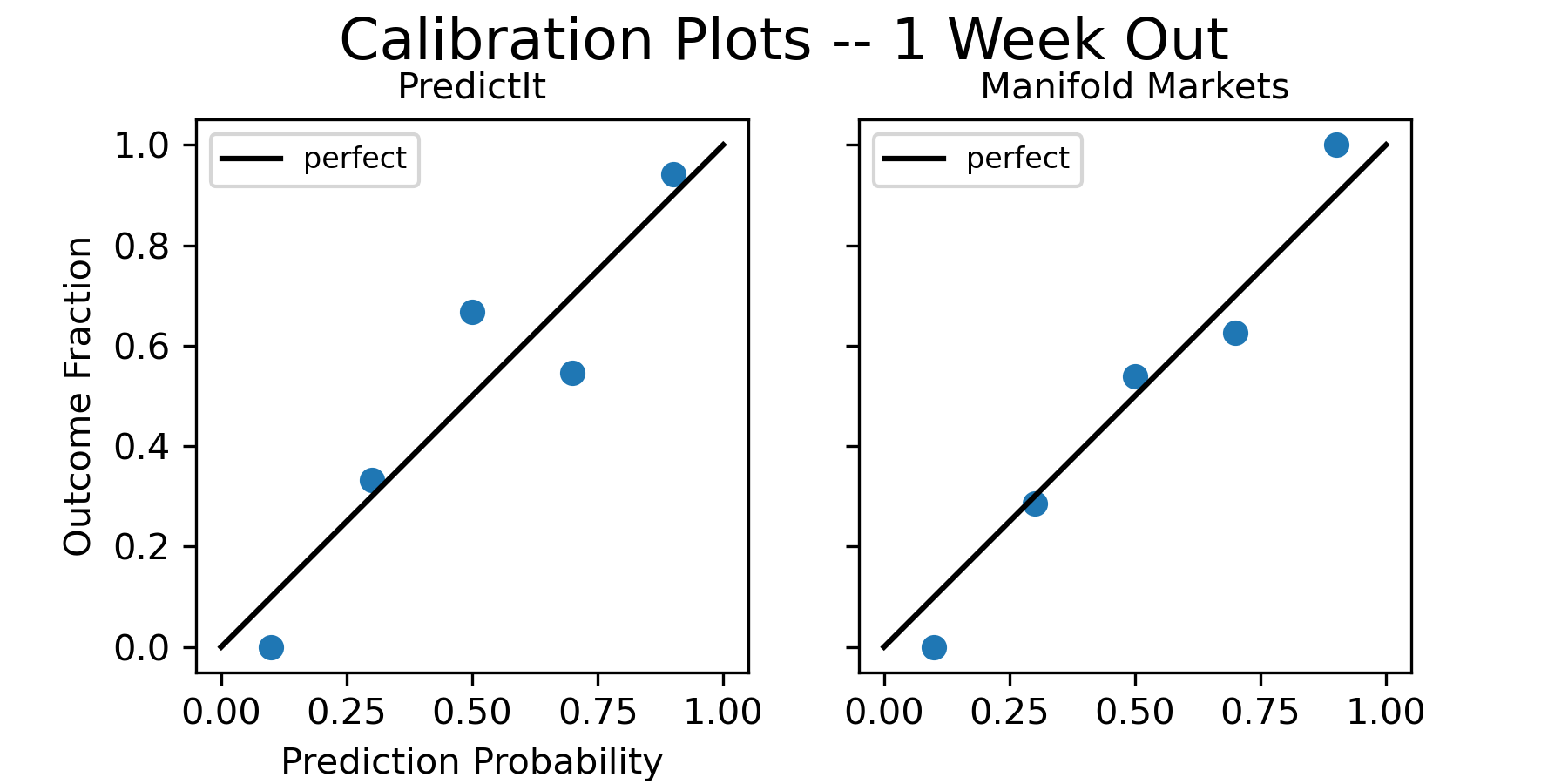
And here are the calibration plots the day before the election:
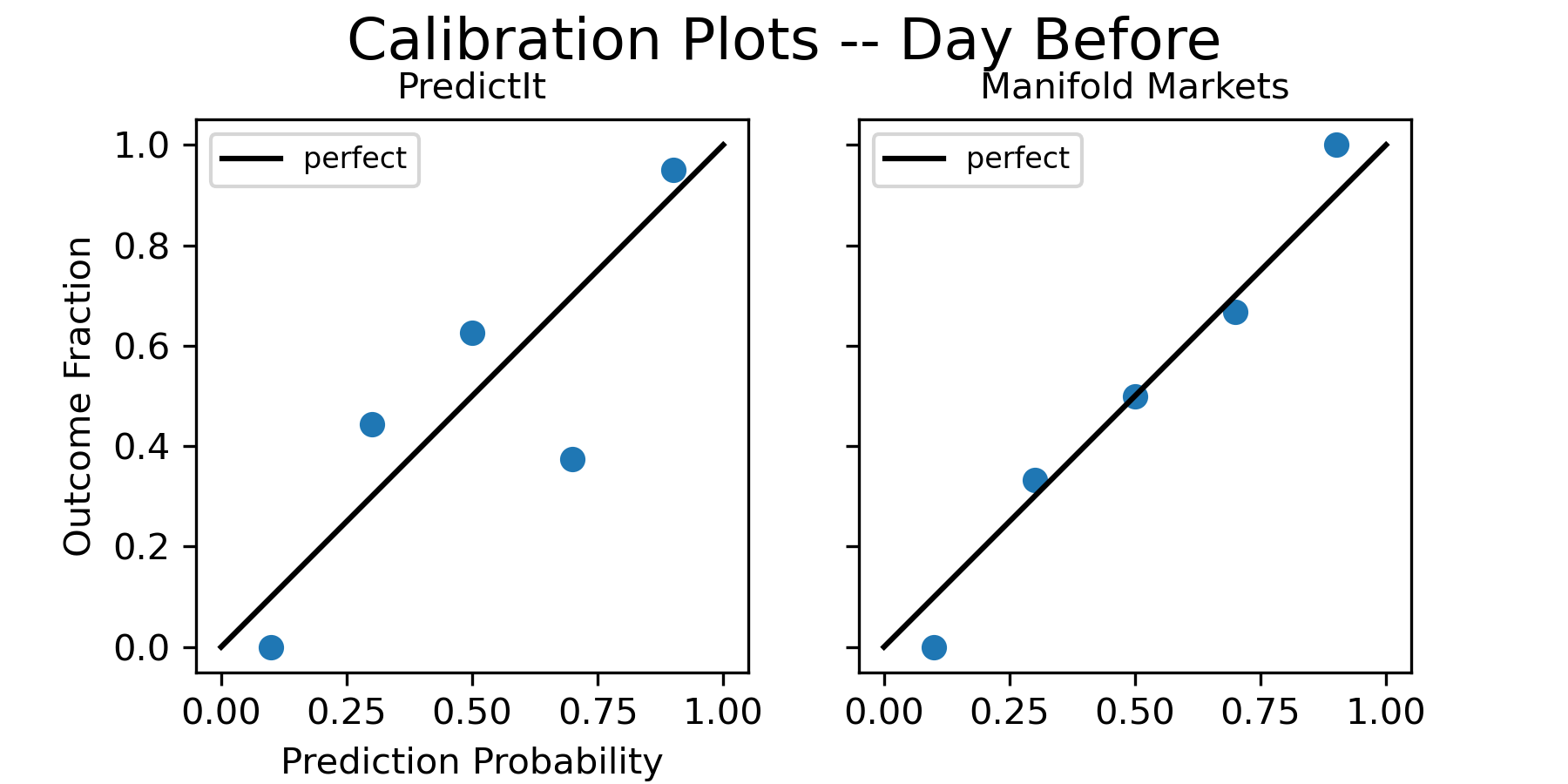
Here is the table of Brier scores, compared to both controls:
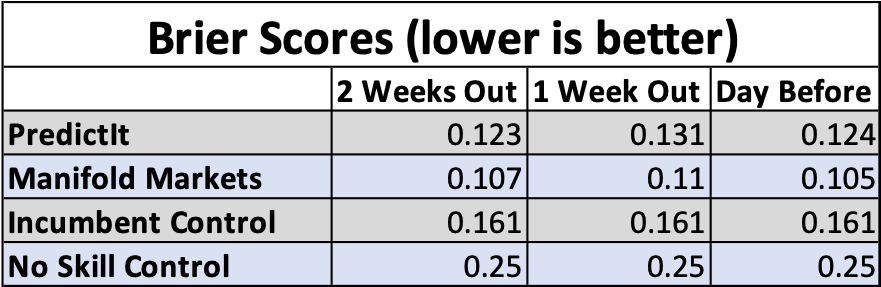
Conclusion
I don’t really have any big conclusion here. Like I said, I don’t have anything new to say in terms of theory or insights into why the forecasts performed a certain way. My goal here is to do the meticulous work of collecting the data, crunching the numbers, and reporting the results in case people are interested.
Again, I’ll repeat exactly what I said in the intro: I would be super cautious here about extrapolating from these results. The dataset is just too small to draw any strong, general conclusions about the relative performance of PredictIt, FiveThirtyEight, and Manifold Markets. However, if people are interested in this type of analysis, I’ll keep doing it during future election cycles, and maybe some consistent patterns will emerge.
Methodology
I kinda feel weird trying to explain something when someone else has already done a better job of explaining it than me – I’d rather just refer people to the best possible explanation of the thing. In this case, this lecture from Phillip Tetlock does a better job of explaining the problem formulation, calibration plots, and Brier scores than I can – he also has a great book on the topic.
With that being said, I’ll still provide some explanations here in case you don’t feel like watching a lecture or reading an entire book.
Data Collection
Before we get into the metrics, I’ll say a bit about the data and how it was collected. I collected the data the old-fashioned way, by actually going to these sites and typing the forecast probabilities into an Excel spreadsheet 2 weeks, 1 week, and 1 day before election day.
To be precise, I checked these websites between 9am and 10am on these days, and made a screen capture recording showing all of the forecast probabilities, so that I have an official record of the data that people can go back and check if they want to. Then, I rewatched this recording later and manually typed the probabilities into an excel spreadsheet. The screen capture recordings documenting the forecast probabilities are available in this video on my Youtube channel.
Although the whole process was a bit of a pain, I think it was the best way to get data for an apples-to-apples comparison between the sites. It was important to get forecasts at the same time (give or take a couple minutes) in order to make a fair comparison.
I also figured the best time to collect the data was before election day, while the markets were still active. That seemed a lot easier than trying to submit a request for the data afterwards, which might have been rejected, or may not have included data at the timepoints I wanted. For example, a while ago I actually submitted a request for data from PredictIt, filled out a form they gave me, and never heard back about it. So as far as I’m concerned, the low-tech approach of actually looking at the prices and manually recording them seems like the best option.
A couple notes about the data:
The spreadsheet only includes questions for which there was an overlap between PredictIt and FiveThirtyEight, or between PredictIt and Manifold Markets. So if a question wasn’t forecast on PredictIt, or was only forecast on PredictIt, then it isn’t included in the spreadsheet or my analysis here (a consequence of this is that I’m really only looking at Senate and Governor races, not House races).
The election for Alaska governor was too weird this year – had 4 people running, including 2 Republicans and an Independent. So I just excluded this one entirely.
In the Utah Senate race, Evan McMullin is technically an Independent, but was endorsed by the Democratic Party, so I’m counting him as a Democrat for the purposes of the analysis.
Three of the PredictIt governor markets were worded differently than the others (Texas, Florida, Massachusetts). Instead of asking which party would win, these markets asked which specific candidate would win (I guess because the market originally opened before the primaries). Anyway for these three markets, I changed the wording in my spreadsheet to “Which party will win…” and added a “***” to denote that I’d changed the wording. Then I just used the prices for the party nominees winning to fill in the prices for each party winning.
Several Manifold Markets forecasts were only added in the last week before the election, and didn’t exist when I went to check the site 1 and 2 weeks before election day. So I excluded those markets from the PredictIt vs Manifold Markets section, although the data for them is still included in the spreadsheet.
I considered the outcomes to be resolved when they were called by a major media source, even if the betting markets haven’t officially closed and paid out yet. If anything crazy happens, like a race turns out to have been called wrong and gets reversed, I’ll redo the analysis and edit this post to account for it.
All of the elections are double-counted since they have one question forecasting the probability of a Democrat winning and another forecasting the probability of a Republican winning. In some cases, the PredictIt forecasts for these don’t add up to 1. Manifold Markets only had one question per election, so I filled in the probability for the corresponding other question by subtracting the first-question forecast from 1.
Again, you can find the data spreadsheet on my Github and the screen capture recording of the data on my Youtube channel.
Data Format: Probabilities and Outcomes
In forecasting, the prediction of an event happening or not happening is usually given in the form of a probability. For prediction markets, these are typically prices (like cents on the dollar) that can also be viewed as probabilities ($0.20 corresponds to a probability of 0.2). The outcomes can be labeled with 1 and 0 depending on whether the event happens or not.
So, whether we’re talking about sports, elections, current events, or something else, most forecast or prediction market datasets with binary yes/no outcomes can be represented in this format:

The data spreadsheet includes other information, like the actual question being forecast, but in order to calculate the evaluation metrics all you really need is the forecast probability and 0/1 outcome.
Calibration Plots
A common objection people first have to probabilistic forecasts is that it seems impossible to say if they’re correct or not. For example, let's say a forecaster estimates a 40% chance that a candidate will win an election, and they end up winning. Does that mean the forecaster got it wrong? Well, no. 40% chance isn't 0%. But we can't exactly say they got it right either.
But let's say the forecaster has made hundreds of probability estimates for different events. Then, we can look at all of the events they estimated 40% for. If those events ended up happening about 40% of the time, that means the forecaster is well-calibrated.
A calibration plot is a visual representation of this. The horizontal axis shows the binned forecast probabilities for different events, and the vertical axis shows the fraction of the time that those events actually ended up happening. The diagonal line up the middle is what a perfect forecast calibration would look like (events predicted with 0.3 probability happen 30% of the time, 0.4 probability happen 40% of the time, and so on…).
The binning of the probabilities just means that, for example, events forecast with probabilities anywhere between 0.2 and 0.3 would all be put in the 0.25 bin, so that we have enough samples to calculate the outcome fraction within that bin.
Here are two examples of calibration plots (taken from earlier in the report):
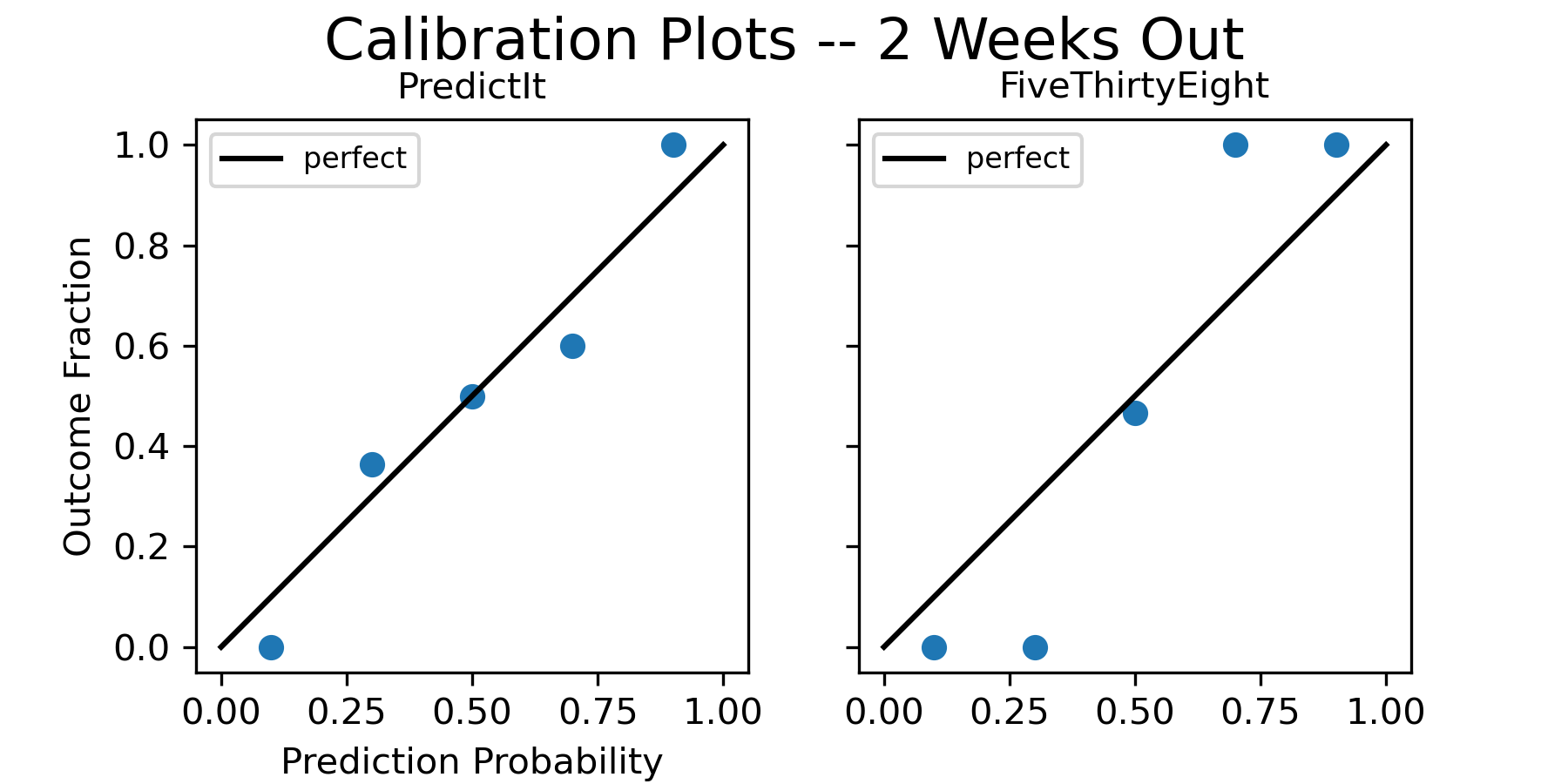
I hope this explanation is clear and makes sense, but just in case it doesn’t, I’m going to again refer you to this lecture by Philip Tetlock, who I think does a better job of explaining these concepts than me.
Also, like I said before, calibration plots are a useful visualization tool, but they can be misleading if the bins don’t have an equal number of observations in them. For example, in the above plot, it looks like PredictIt performed better, but as we saw previously in the report FiveThirtyEight’s forecast actually had the better Brier score, since more of their forecast probabilities were in the 0.1 and 0.9 bins. So if the calibration plots and Brier scores seem to differ, you should trust the Brier scores.
Brier Score
Calibration plots are useful for visualizing the forecast’s performance, but we also want a numerical score for the performance. The most commonly used metric for this is the Brier score. Here is the formula:
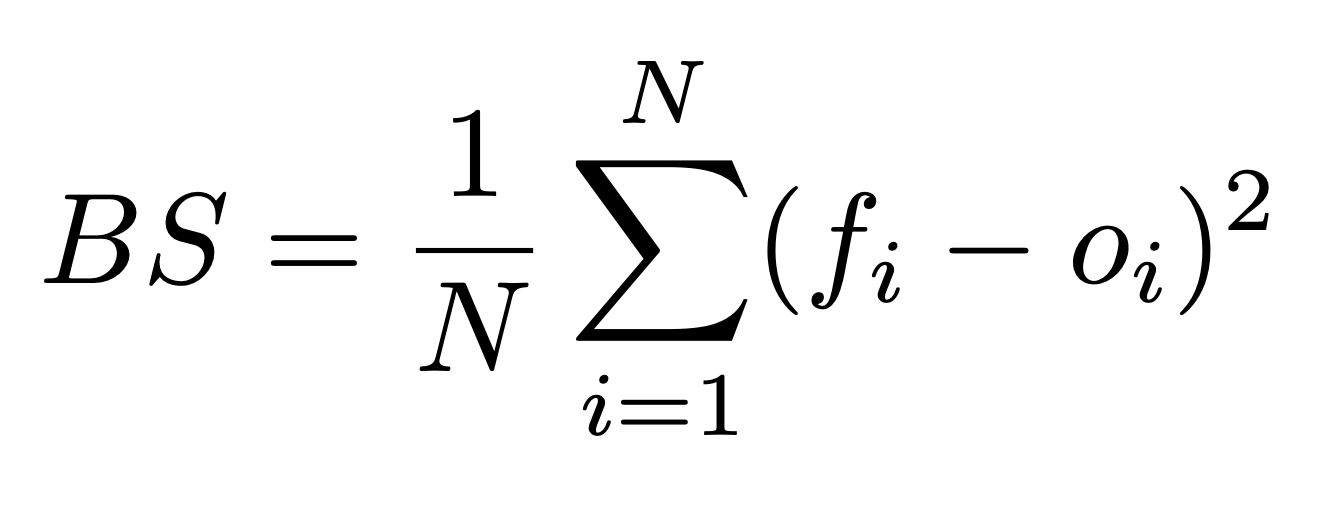
Here, N is the total number of predictions, f_i is the prediction probability, and o_i is the true outcome of the event (either 1 or 0). (Sorry about the awkward notation, I haven’t really been able to find a good way to write math notation like subscripts and stuff on Substack.)
Basically, this is just a measure of the forecast’s average squared deviation from the true outcomes of the events being predicted. The lower the Brier score, the better the forecast, and a perfect score is 0.
Conflict of Interest Statement
I’m a fan and supporter of all three of these sites, as well as a user of PredictIt. In this election cycle, I had bets placed on 3 PredictIt markets, although two were markets not included in this analysis (because FiveThirtyEight and Manifold Markets didn’t have a forecast for it), and the other bet was placed on election day, after I had already finished recording all of the forecast data. So I don’t think either of these 3 bets could have influenced the results of this analysis.
Also, I’m an “independent” (not a member of any party), and voted for a mix of Democrats, Republicans, and Libertarians in this election.
Further Reading
Superforecasting: The Art and Science of Prediction by Phillip Tetlock and Dan Gardner. AMAZING BOOK!! Really the best introduction to forecasting.
The Signal and the Noise by Nate Silver
“A Bet Is a Tax on Bullshit” – Marginal Revolution post by Alex Tabarrok
Idea Futures by Robin Hanson
Introduction to Prediction Markets, by Jorge I. Velez
Scott Alexander’s Prediction Market FAQ
Thanks Mike, I would be interested to hear why you don't think ROC curves are an appropriate metric for assessing predictive competency. I watched the Philip Tetlock lecture and came out thinking that they would be.
Another analysis of midterm forecasts from First Sigma, which includes more sites (including Polymarket and Metaculus), but fewer forecast questions:
https://firstsigma.substack.com/p/midterm-elections-forecast-comparison
Very interesting post to check out!