
2 Types of Forecast Accuracy

Coin Flip Game
Imagine two people – I’ll call them Partially-Psychic Pete and Just-A-Regular-Guy John – are playing a game where they take turns attempting to make predictions about a fair coin toss by forecasting the probability that it will come up heads.
Pete is both partially-psychic and overconfident. When it’s his turn, he always forecasts 1 or 0 for the probability of heads, and he gets it right 60% of the time. So Pete’s predictions look like this (an outcome of 1 means heads, and 0 means tails):

Except imagine a thousand or so predictions with 60% of them being correct.
John, on the other hand, is not a psychic, and correctly judges his own uncertainty about the coin toss. When it’s his turn, he simply gives a forecast of 0.5 probability of heads each time. His predictions look like:

Again, imagine a thousand or so predictions like this.
So, who’s the better forecaster? Who’s better “calibrated”?
In one sense Pete’s the better forecaster. He’s actually partly psychic and his predictions add new information about what we should expect for the outcome. In another sense, John’s the better forecaster, since he’s judging his own certainty correctly — he predicts 0.5 probability of heads, and the coin does indeed come up heads 50% of the time.
This is a minor pet peeve I have when it comes to forecast evaluation. When we talk about accuracy/calibration, we’re actually talking about two different things that are kinda related, but can also be separated from each other. Something about the imprecise language around this bothers me.
Has anyone written about this before? I couldn’t find anything, but if so please let me know so that I can cite them and use their terminology. But for now, I’m going to refer to Pete’s type of accuracy as Correct Prediction Accuracy and to John’s type of accuracy as Uncertainty Judgement Accuracy.
As we just saw in the example, it’s possible to have a good — even perfect — Uncertainty Judgement Accuracy, while having terrible Correct Prediction Accuracy (John correctly judged the fact that he didn’t have any information about the outcome of the coin flip beyond random chance). You can also have very impressive Correct Prediction Accuracy (literally being psychic with 60% accuracy on a fair coin flip) and still have terrible Uncertainty Judgement Accuracy.
How do Brier scores handle this?
Brier scores are the most commonly used (and best, in my opinion) metric for forecast evaluation. The formula is:
Here, N is the total number of predictions, y_i is the prediction probability, and o_i is the true outcome of the event (either 1 or 0). (Sorry about the awkward notation, I haven’t found a way to write the subscripts on Substack.)
Basically, this is just a measure of the forecast’s average squared deviation from the true outcomes of the events being predicted. The lower the Brier score, the better the forecast, and a perfect score is 0.
Brier scores incorporate both Correct Prediction Accuracy and Uncertainty Judgement accuracy — you’re rewarded for predicting the outcome correctly and correctly judging your own uncertainty won’t get you a perfect score, but you’re also punished for overconfidence. This combination is kinda good in the sense that it makes Brier scores a useful measure of overall forecast performance. But it’s also kinda bad in the sense that it includes an implicit tradeoff between the two that is somewhat arbitrary.
Let’s go back to the coin flip example. Remember that Pete is overconfident and gives probability 0 or 1 every time, and gets it right 60% of the time. John correctly judges his own uncertainty, and gives a probability of 0.5 every time.
Under these conditions, Pete’s Brier score is 0.4 and John’s Brier score is 0.25 (just trust me for now, in the next sections we’ll calculate through computer simulations and on paper). Remember, lower is better, so John has the better Brier score — his correct judgement of his own certainty is enough to beat Pete’s correct predictions of the outcome.
But what if instead of getting it right 60% of the time, Pete was getting it right 80% of the time? Under those conditions, Pete’s Brier score would be 0.2 — better than John’s score of 0.25! Apparently 80% correct, even when overconfident, is enough to outweigh John’s perfect judgement of his own uncertainty.
What if Pete was getting it right 75% of the time? Then his Brier score would be 0.25, equal to John’s score. Here’s all of that in a nice table:
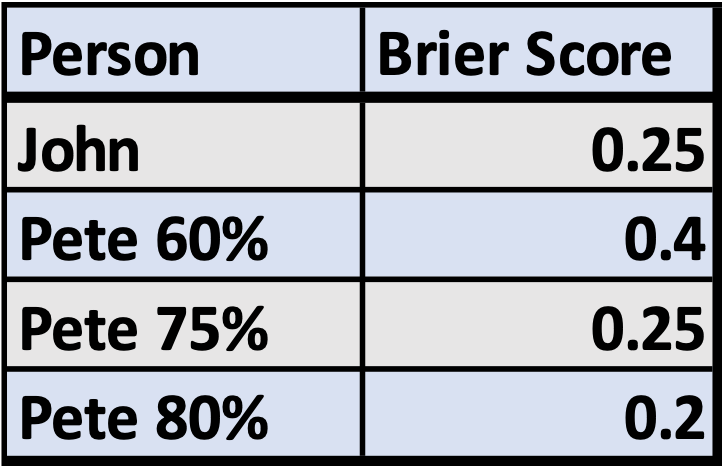
Anyway, I still think Brier scores are probably the best method we currently have for evaluating forecasts, but it’s important to be aware of these two types of accuracy, and the implicit tradeoff that Brier scores make between them.
Python Simulation of Coin Flip Game
Here’s a Python program you can use to simulate the coin clip game, and compute Brier scores for the players, setting any correctness probability you want for the partial-psychic Pete. I think you should be able to copy and paste this directly into a .py file and run it, but if anyone’s having trouble let me know and I’ll just put it on Github instead.
import random
def brier_score(y_true,y_score):
# check to make sure predictions and outcomes are the same size
assert len(y_true) == len(y_score)
# N = total number of coin tosses
N = len(y_score)
# summing up squared difference between prediction prob and outcome
total = 0
for i in range(N):
total += (y_score[i] - y_true[i])**2
# dividing by total number of coin tosses
total = total/N
return total
# 1 for heads, 0 for tails
y_true = []
# forecasts 0.5 every time (John in the story)
control = []
# forecasts 0 or 1 every time, but getting it right with some prob
# (Pete in the story)
partial_psychic = []
## How often does the overconfident partial-psychic get it right?
psychic_correct_prob = 0.6
# psychic_correct_prob = 0.75
# psychic_correct_prob = 0.8
num_coinflips = 1000000
for i in range(num_coinflips):
# random draw, 1 is heads, 0 is tails
draw = random.randint(0,1)
y_true.append(draw)
# control forecasts 0.5 probability of heads every time
control.append(0.5)
# psychic forecasts 0 or 1, and gets it right with some prob
if random.random() <= psychic_correct_prob:
partial_psychic.append(draw)
else:
partial_psychic.append(abs(1-draw))
print(f"Control Brier Score: {brier_score(y_true,control)}")
print()
print(f"Psychic Brier Score: {brier_score(y_true,partial_psychic)}")Computing Brier Scores on Paper
[WARNING!! MATH AHEAD!! Seriously though, this section is just some optional extra information and can be skipped.]
This is a brief explanation of how to use some basic probability theory to compute Brier scores for the coin flip game on paper. We’re going to use a concept known as expected value. The expected value of a random variable is the average of all of the possible values of the random variable, weighted according to their respective probabilities:
Here, X is the random variable, x_1, x_2, …, x_n (sorry again, can’t write subscripts on Substack) are the possible values that X can take, and p_1, p_2, …, p_n are the respective probabilities of X taking those values. By convention, the angle brackets <> are used to denote the expected value of a random variable.
Let’s take a concrete example. Let’s say you’re playing a game where you can win $2 with probability 0.5, $10 with probability 0.3, and $20 with probability 0.2. Your expected winnings are $8:
Alright, now let’s take another look at that Brier score formula:
Basically, the formula is taking the average of (y_i - o_i)^2 (again sorry for the awkward subscript notation here). Remember, y_i is the forecast probability of the coin coming up heads, and o_i is the outcome, either 0 (tails) or 1 (heads), for each flip of the coin, with N flips total.
Let’s define a new random variable now, to represent the difference between y (forecast probability) and o (outcome):
Remember how we said the Brier score is just the average of (y_i - o_i)^2? Well now we can write the Brier score as the expected value (average of the outcomes weighted according to their probabilities) of our new variable X squared:
Ok, let’s try using this approach to actually calculate the Brier scores for Pete and John. Remember, John forecasts 0.5 chance of heads every time. So if the coin comes up heads, then X = (y_i - o_i) = (0.5 - 1) = -0.5. If it comes up tails, then X = (y_i - o_i) = (0.5 - 0) = 0.5. So,
We can then compute the expected value of X squared by simply squaring both of the outcomes and taking the average, weighted according to their respective probabilities:
And so we’ve confirmed John’s Brier score of 0.25.
What about Pete? Remember Pete is an overconfident partial-psychic who forecasts 0 or 1 every time, and gets it right some percentage of the time. Let’s use a constant parameter “f” for Pete’s probability of getting it right. Let’s think again about our random variable X, which measures the difference between the forecast probability and the outcome. In Pete’s case, X will be 0 with probability f — those are the times he’s getting it right. He’s getting it wrong with probability (1-f). Half of these times he’s forecasting 1 and it comes up tails (0), so X will be 1 with probability (1-f)/2. The other half of the his incorrect guesses will be a forecast of 0 and it comes up heads (1), so X will be -1 with probability (1-f)/2. So,
Remember, to find the Brier score we need the expected value of X^2. Again, we can find this by simply squaring all of the outcomes and taking their average, weighted according to their respective probabilities:
So if Pete is forecasting 0 or 1 every time, and getting it right with probability f, then his Brier score is 1-f. We can use this formula to recover the Brier scores listed in the table previously. If his probability of getting it right is 0.6, then his Brier score is 0.4. If his probability of getting it right is 0.75, then his Brier score is 0.25. If his probability of getting it right is 0.8, then his Brier score is 0.2.
Further Reading
Superforecasting: The Art and Science of Prediction by Phillip Tetlock and Dan Gardner. AMAZING BOOK!! Really the best introduction to forecasting.
The Signal and the Noise by Nate Silver
“A Bet Is a Tax on Bullshit” – Marginal Revolution post by Alex Tabarrok
Idea Futures by Robin Hanson
Introduction to Prediction Markets, by Jorge I. Velez
Scott Alexander’s Prediction Market FAQ
I made a related comment on your post about 538 calibration which is basically: who would the superior gambler be? Partially-Psychic Pete or Just-A-Regular-Guy John?
At fair odds, presumably Pete...
But it gets interesting if the odds aren't even, right? Let's say it's like 1:99 odds tails and 99:1 odds heads (stupid bookie). John always takes the big payout and 50 times out of 100 wins. That probably beats Pete (who 40% of the time incorrectly takes the tiny payout). Right?
My math isn't strong enough here but I'm curious where the line is in terms of odds unevenness before John is favoured. My intuition says it's tightly related to Pete's overconfidence... I think I need to try some simulations or write this down properly...
Great post Mike. Although I'm a fan of empirical track records, it seems that there are a lot of concerns that normal scoring rules don't capture. While it might not cover exactly the topic you touched on, I think you might enjoy this paper on Alignment Problems With Current Forecasting Platforms by Nuño Semperea and Alex Lawsen (https://arxiv.org/pdf/2106.11248.pdf). You might also enjoy my recent post about problems with forecasting tournaments (https://abstraction.substack.com/p/against-forecasting-tournaments).